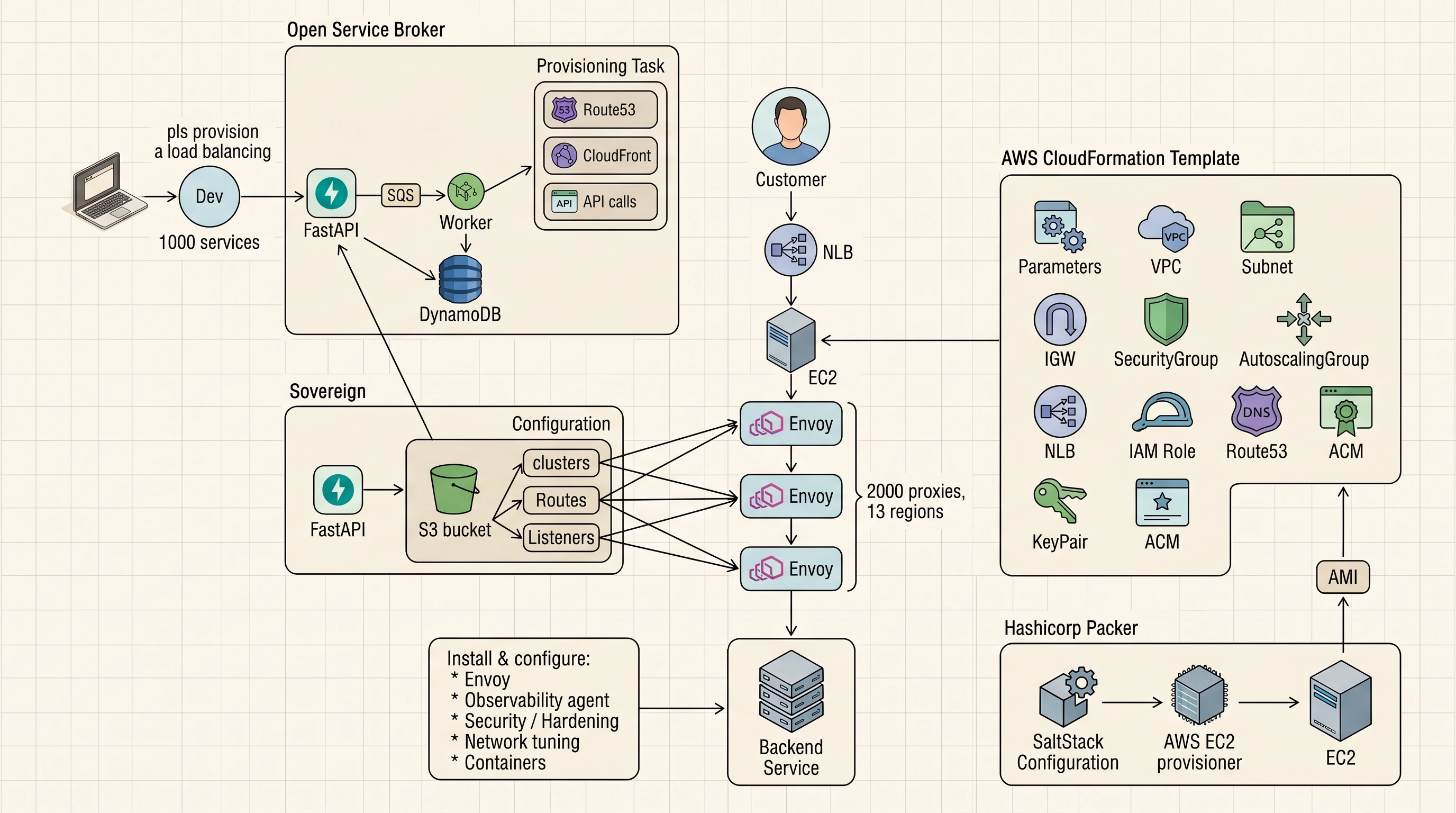
A self-service edge built on an Open Service Broker, an Envoy xDS control plane, and an AMI pipeline — replacing a paid load-balancer product with an open-source platform 2,000 proxies wide.
- The Open Service Broker API gives the platform a tiny, boring HTTP surface for developers:
provision,update,deprovision. - Envoy + xDS turn a proxy fleet into something reconfigurable at runtime — that's what makes "self-service" actually self-service.
- Sovereign, an open-source FastAPI control plane, translates broker state into Envoy config via templates + context.
- The whole fleet is baked into an AMI by Packer + SaltStack and rolled out by an ASG — boring, reproducible, fast.
- Cross-cutting concerns (auth, authz, rate limiting) live as sidecars on each Envoy box. Different teams, same plug points.
Last week Vasilios Syrakis published a retrospective on the eight years he spent at Atlassian after being affected by the recent layoffs. The video is part career reflection, part architecture walkthrough. I'm going to skip the career half and focus on the architecture, because the architecture is a clean example of a small platform team replacing a paid, click-ops load balancer product with an open-source self-service edge — and the shape of what they built generalises to most companies running a lot of microservices.
I watched it, took notes, and pulled them into this so you don't have to scrub through 38 minutes of whiteboard drawings.
The problem he was hired to solve
The team needed an internal application that would let developers self-serve their own load balancers. Think AWS Application Load Balancer, but inside Atlassian, on top of their own infrastructure. In the interview Vasilios said he could build it in Python. They believed him. He joined.
Two weeks in, he started on what became the foundation of the team's product for the next eight years: an Open Service Broker.
The Open Service Broker
What is an Open Service Broker?
The Open Service Broker API is a spec — originally from Cloud Foundry, later adopted by Kubernetes — that defines a small HTTP API for provisioning resources on demand. A catalog endpoint plus provision, update, deprovision, bind, unbind. That's the whole API. Think "Stripe but for internal infrastructure."
Vasilios built Atlassian's broker as a Python web app. The first version used connexion, a library that reads an OpenAPI spec and wires up Flask routes for you. It later migrated to plain Flask, then to FastAPI, which is where it still lives.
The broker's internal architecture is the canonical async-job-queue setup:
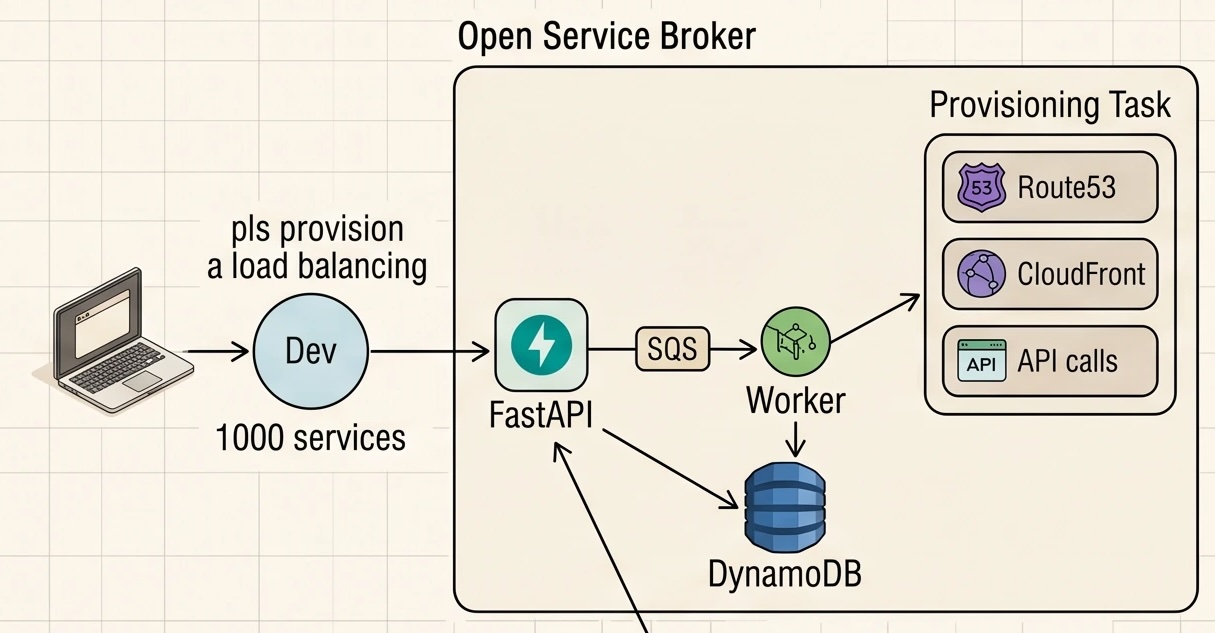
When a developer asks for a load balancer, the FastAPI process doesn't try to do the work in-band. It drops a task onto SQS, records "pending" in DynamoDB, and returns immediately. A worker picks the task off SQS, does the side effects (DNS records, a CloudFront distribution, whatever), and writes the resulting state back to DynamoDB. The client polls the broker until the status flips to ready or error.
Nothing exotic here, and that's the point. The broker is a thin, boring control surface. The interesting work happens downstream.
Why Envoy
At some point an architect proposed a bigger idea: rip out Atlassian's commercial, license-fee load balancers and replace them with a fleet of open-source proxies the platform team would own end to end.
They chose Envoy. If you've used Nginx, Envoy is in the same family but with one critical difference: it has a dynamic configuration API. You can stand a proxy up once and reconfigure it at runtime (new routes, new clusters, new TLS certs, new rate-limit rules) without a restart.
That is the entire reason self-service works. Without it, every developer change would mean a deploy of the proxy fleet, which means a ticket, which means it isn't self-service — it's just a self-service-flavoured ticket queue.
What is xDS?
Envoy's config API is called xDS ("x Discovery Service" — a family of APIs: CDS for clusters, RDS for routes, LDS for listeners, EDS for endpoints, etc.). The proxy connects to a control plane and continuously asks "what should I be doing right now?". The control plane streams back the current desired state. If you've ever wondered how Istio works under the hood, this is the same mechanism. Spec.
The xDS control plane (Sovereign)
Atlassian's xDS control plane is its own Python service, also FastAPI. Vasilios open-sourced it on Bitbucket under the name Sovereign.
Sovereign's job is to translate the broker's view of the world into Envoy configuration. Three inputs, one output:
- Templates. Jinja-style descriptions of Envoy resources (clusters, routes, listeners) with placeholders for the parts that vary per service.
- Context. The dynamic data that fills those placeholders. Some of it comes from the broker's DynamoDB, some from S3, some from elsewhere.
- Polling. Sovereign periodically refreshes its context from those sources, re-renders templates, and serves the resulting Envoy resources over the xDS API.
When a developer's request flows through broker → SQS → worker → DynamoDB, Sovereign eventually picks up the new state and pushes a fresh config to the relevant Envoy proxies. The proxy starts routing the new traffic. No restart, no manual change, no ticket.
The full picture so far:
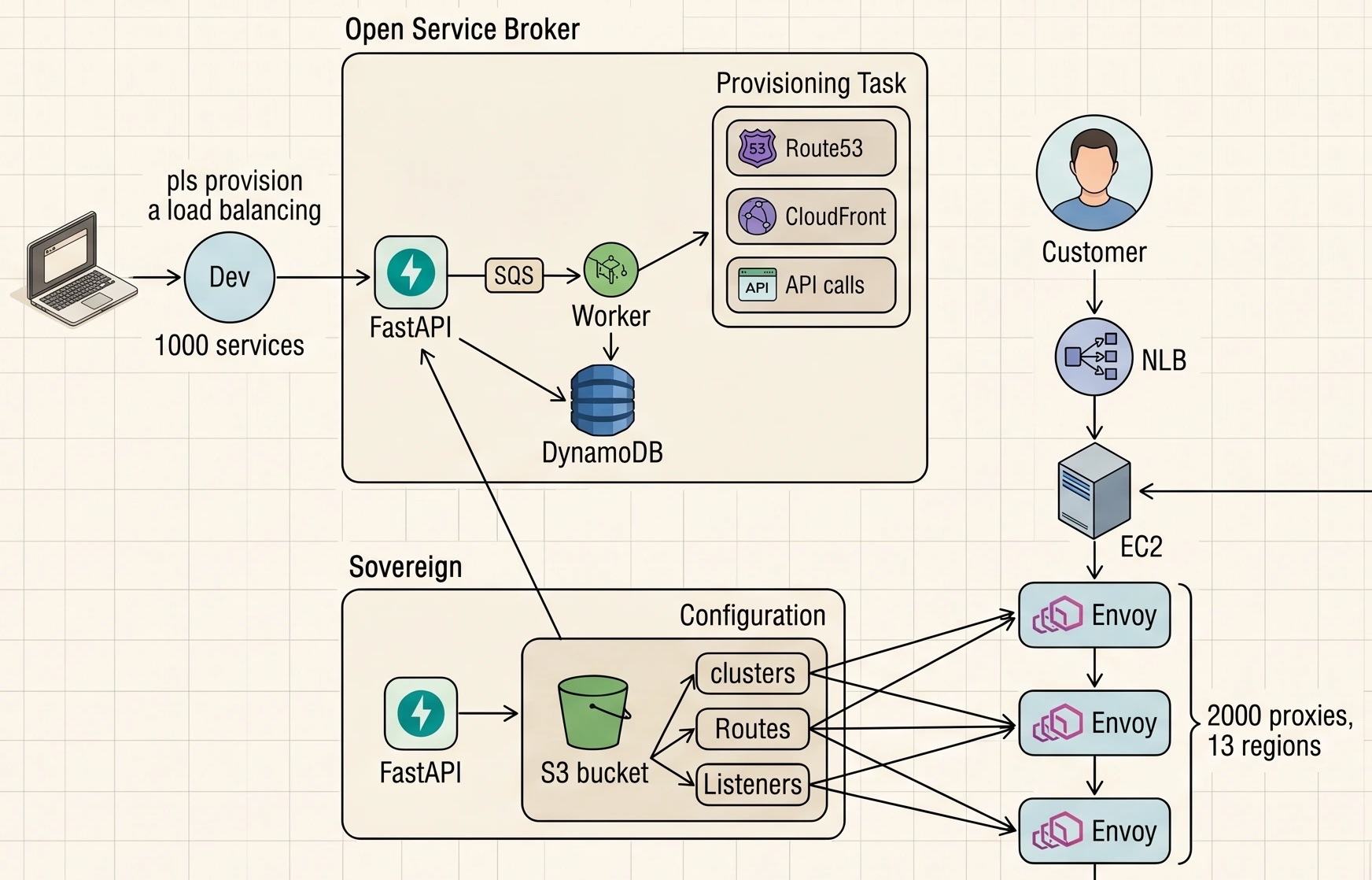
One thing worth flagging: a poll-based control plane sounds primitive next to xDS's streaming model, but it works, and it's easier to reason about than push-based reconciliation. I'd take this over a more clever design.
The AWS infrastructure
The Envoy fleet itself was provisioned with CloudFormation. Plain infrastructure-as-code, no surprises. The resources are the ones you'd guess: VPC, subnets, internet gateway, security groups, IAM role, key pair, Auto Scaling Group, an NLB in front (layer 4), ACM certs, Route 53 records.
The scale he mentions: roughly 2,000 proxies across ~13 regions. The ASG is the unit of fleet management. What makes the fleet identical and reproducible is the AMI those instances boot from.
Baking the AMI
The AMI is its own pipeline. Two tools:
- HashiCorp Packer drives the workflow. It launches a temporary EC2 instance in a dev account, runs a provisioning step, then snapshots the instance into an AMI.
- SaltStack, a configuration-management tool in the Ansible/Puppet/Chef family, does the provisioning step itself: install packages, drop config files, enable services, declaratively.
What goes onto the image:
- Envoy itself, installed and pre-configured
- Logging agents
- Security hardening
- Network tuning
- Container runtime
- Observability agents for logs, traces, and metrics
- The sidecar binaries (more on these below)
CloudFormation references the resulting AMI ID. When the ASG launches an EC2, the instance comes up with everything already on it; runtime parameters like secrets and keys are injected at boot. Within a minute or so it's accepting traffic.
This was, in Vasilios's words, "essentially the first two years of work."
What came next: migration, then features
With the foundation in place, the team turned to getting customers onto it. Two parallel pushes:
- Big products. Jira, Confluence, Bitbucket, Statuspage, others. These have special cases a generic multi-tenant platform doesn't handle out of the box — caching rules, header rewriting, region-specific routing — so a lot of templated-configuration work happened here.
- All the other microservices. This was actually easier, because the platform team could force the issue. Previously, services got a very basic load balancer by default, which meant a service could be exposed to the public internet without anyone meaning to. The platform changed the default: the basic load balancer would no longer expose you publicly. To be public, you had to opt in by configuring routing through the new centralised infrastructure.
That second point deserves a beat. They turned a load-balancer migration into a security win. Public exposure went from "thing that happens by accident" to "thing you have to ask for explicitly." That kind of secondary benefit is much easier to design in than to retrofit, and most platform migrations leave that value on the table.
Edge compute and sidecars
Once the migration was done, the team had something powerful: every public request from every Atlassian customer flowed through the same Envoy fleet before it hit a service. Anything you implement there, you don't have to implement (badly, inconsistently, and a thousand times) inside every backend team.
So they pushed cross-cutting concerns to the edge:
- DDoS protection: CloudFront sitting in front of the NLB. Built by a colleague.
- Access logging: native to Envoy via its HTTP Connection Manager filter. A developer submits a tiny JSON config; the templates expand it into the full Envoy access-log setup.
- Authentication: a sidecar Vasilios wrote in Rust, running on the same instance as Envoy.
- Authorization: a sidecar built by another team, same pattern.
- Rate limiting: a sidecar built by yet another team, same pattern.
How does Envoy talk to a sidecar?
Through its extension points — most commonly the external authorization filter and the external processing filter. Envoy is extensible inside its own process model (C++, WASM, Lua filters), but external sidecars let teams ship on their own cadences, in their own languages, with their own on-call rotations. Envoy makes a gRPC call out per request; the sidecar approves, rejects, or rewrites; Envoy continues.
The mental model:
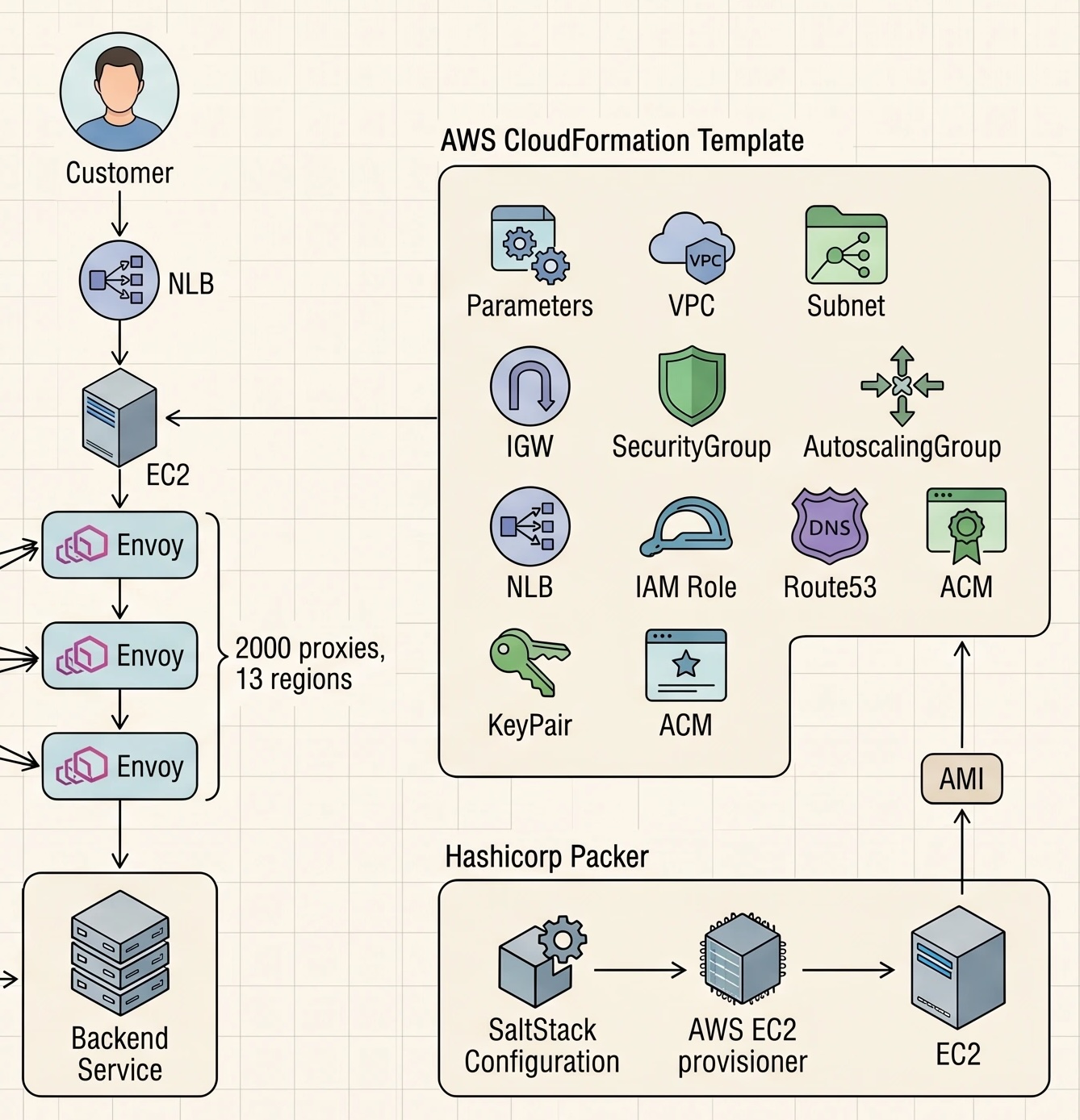
When a request lands, Envoy hands it to the auth sidecar to verify the user, the authz sidecar to check permissions, and the rate-limit sidecar to enforce quotas — all before the request reaches the backend. The backend just sees an authenticated, authorised, throttled request.
The timeframe
- Year 0–2: build the broker, build Sovereign, design the CloudFormation + Packer + SaltStack pipeline, get the first proxies running in production.
- Year 2–~5: migrate the big products and every microservice onto the platform. Add the features needed to support real customer special cases.
- Year ~5–8: edge compute features (sidecars for auth/authz/rate-limiting), deeper Envoy extension work, then a compliance-driven phase he describes as "tedious and boring" but necessary.
Challenges, in the speaker's own framing
Information firehose. Standard at any large company, but worth naming, because the answer isn't "absorb everything before you start." It's "start building, and let the building force the learning."
Envoy's surface area. Envoy's configuration is enormous. Route matching alone has dozens of knobs; the routing action can send traffic to any cluster on the proxy. The team's job was to expose a small, safe, validated subset to developers: accept a tiny JSON blob, validate it, feed it into a template, produce a known-correct Envoy resource. That validation layer is where a surprising amount of the engineering effort lives in any platform like this, and it's the part that's usually under-staffed.
Multi-tenant special cases. Generic platforms always run into the largest tenants having unique requirements. He spent a couple of years on this.
Maintenance and churn. This was his most interesting non-architectural point. In any long-lived codebase you can predict where the churn will concentrate, and the areas with churn are smells — they signal complexity that's about to grow. Spotting churn early and refactoring before it metastasises is the long-term skill. He also flags an open question: will vibe-coded and AI-assisted apps have the same maintenance burden, or something different? He's not optimistic but is open to being wrong. I'm not sure either, and I think anyone claiming certainty here is selling something.
People stuff. He's honest that personality conflicts cost him performance at times, and that mentoring an intern — successfully, by the metric; they got the top rating — still left him uncertain whether he'd done it well, because he'd never been mentored himself. The contrast he draws between training (which he's good at) and mentoring (which he found harder) is a useful distinction I hadn't thought to make.
Takeaways
The thing I keep coming back to is that none of this works without dynamic configuration. xDS is the load-bearing piece. The moment your data plane can be reconfigured at runtime, the platform team stops being a ticket queue and becomes an API. Everything downstream of that — the templates, the sidecars, the security defaults, all of it — depends on that one property. If you're designing a platform and your data plane needs a deploy to change, you don't have a platform, you have an internal product with extra steps.
Templates + context
Developers see a small JSON shape. Templates absorb Envoy's complexity. The validation layer protects against mistakes. Same shape as Kubernetes manifests or Terraform modules — narrow surface, wide tool.
Sidecars decouple ownership
Auth was Vasilios's team. Authz and rate limiting were other teams. All three plug into Envoy through the same extension points. Specialised teams ship independently. This is the part I'd most want to copy.
Secure by default, not by exception
The migration turned "public exposure" from a default into an opt-in. It's the kind of secondary benefit that doesn't usually appear in architecture diagrams but matters more than most things that do.
Boring is a compliment
FastAPI + SQS + DynamoDB + CloudFormation + Packer + SaltStack. Nothing exotic. The cleverness is in the wiring, not the parts.
The line that's going to stick with me from the talk: "Building something is easy. Changing it and making sure that you can still change it over time is difficult." Anyone who's been on-call for a five-year-old service knows exactly what he means.
References
- Original video: I was laid off by Atlassian — Vasilios Syrakis (2026)
- Open Service Broker API specification
- Envoy proxy
- Envoy xDS protocol overview
- FastAPI
- Connexion (Python OpenAPI framework)
- Amazon DynamoDB · Amazon SQS · AWS CloudFormation · Amazon CloudFront · Amazon Route 53 · AWS Certificate Manager · Network Load Balancer
- HashiCorp Packer
- SaltStack / Salt Project
- Envoy External Authorization filter
- Envoy External Processing filter